
1. 单行线表达式
字符串表达式
- initcap(akd)把akd的第一个字母转化成为小写
- length(xxx)求xxx的宽度
- substr(ksfkasd,2,4)从数组 ksfkasd 的第三个字符串已经开始撷取宽度为4的数组
- instr表达式回到要撷取的数组在源数组中的边线。
- 句法如下表所示:instr( string1, string2 [, start_position [, nth_appearance ] ] )
- string1源数组,要在此数组中搜寻。
- string2要在string1中搜寻的数组。
- start_position代表string1的哪个边线已经开始搜寻。此参数可选,如果省略默认为1。数组索引从1已经开始。如果此参数为正,从左到右已经开始检索,如果此参数为负,从右到左检索,回到要搜寻的数组在源数组中的已经开始索引。
- nth_appearance代表要搜寻第几次出现的string2. 此参数可选,如果省略,默认为 1.如果为负数系统会报错。
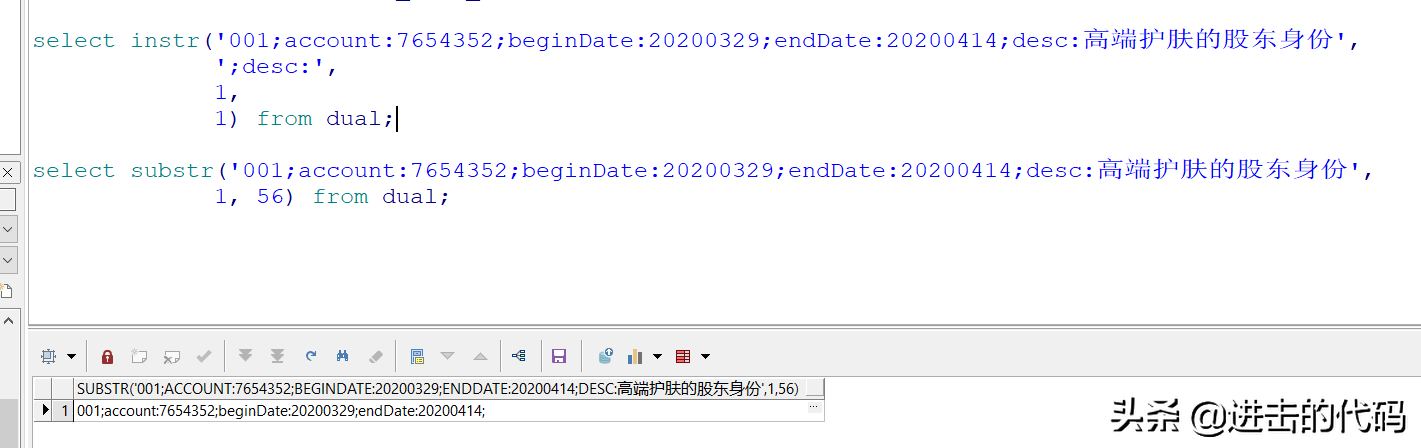
- 注意: 如果String2在String1中没有找到,instr表达式回到0.
- trim(a from adkf)把第一次出现在adfk数组中的a去除 -->只带一个参数时,代表去除数组左右两边的空格
- ltrim(adfsad, ad)左裁剪,结果为fsad -->只带一个参数时,代表去除左边的空格
- rtrim(klsadk, dk)右裁剪,结果为klsa -->只带一个参数时,代表去除右边的空格
- replace(参数一 , 参数二 ,参数三)参数一中出现的参数二替换为参数三,当参数三省略时,参数二会被null替换
数字表达式
- ABS(N)取绝对值
- ceil(n)向上取整
- floor(n)向下取整
- sin(n)正弦
- cos(n)余弦
- sign(n)取符号
- power(m,n)m的n次幂
- mod(m,n)m对n取模
- round(m,n)对m四舍五入,并保留n位小数
- trunc(m,n)对m这个小数进行截断,小数点后面留下n位。不写n表示小数全部截掉
- sqrt(n)开根
- dbms_random.value(m,n)取m--n之间的随机数,是一个小数,小数位数为15 -(n的位数)
日期表达式
- sysdate获取系统日期,默认格式为(DD-MON-RR)天、月、日to_char(sysdate,YYYY-MM-DD HH24:MI:SS) --->结果为:2019-04-22 20:30:44
- add_months(date, i)回到把(i)月份加到(date)日期上的新日期。i可以是任何数字,如果i写成小数,自动撷取整数部分。如果i是负数,则相当于原日期减去i个月。
- next_day(date, char)第一个参数(date)为日期,第三个参数(char)为星期几(中文环境下输中文,英文环境下输英文)。作用是回到date日期后,下一次char对应的日期。例如:select next_day(sysdate, 星期二) from dual;
- last_day(date)回到date日期所在月的最后一天,一般用于判断当月有几天
- month_between(date1,date2)表示date1与date2两个日期间相隔的月份。date1位大的日期,date2位小的日期。
- extract(date from datetime)回到datetime日期对应的date形式。例如: select extract(day from sysdate) --->回到当前日期的的号数。year ----->年month ------>月day ------>日
- trunc(date, format)对日期按format进行截断trunc(25-12月-18, yyyy) 按年进行截断,结果为2018年1月1日(1-1月-18)
转换表达式
- 日期/数字 转换为字符串的表达式:to_char(date , fmt , params)
- date:将要转换的日期;
- fmt:转换的格式;
- params:指定日期的语言(可不写,自动根据操作系统进行改变)
- fmt的参数有:
- YY YYYY --->年
- MM MONTH --->月DD(日期)
- DAY(星期) --->日
- HH24 HH12 --->时
- MI --->分
- SS --->秒
- to_char(1324 , 99999) 把1324转换为数组,参数一最大可以为99999(5位)。如果参数2的位数小于参数一的位数,转换不成功。如果参数二的位数大于参数一的位数,转换后的结果前面不空格。

- 字符串转换成日期to_date(char , fmt , params)
- 参数含义同to_char参数一和参数二的格式需要相同,否则会出现文字与格式数组不匹配的错误
- 字符串转换成数字to_number(char , fmt)参数含义同上
- 日期和日期做减法运算时,不用管格式
to_date(2017/4/5,yyyy/mm/dd)-to_date(2018-5-5,yyyy-mm-dd)- 利用to_char和to_date可以求出某年某月某日是星期
selectto_char(to_date(sysdate,YYYY-MM-DD),day)fromdual其他表达式
- nvl(x,0)如果x的值为空,则回到0
- nvl(x, y, z)如果x的值为null,则回到y的值,否则回到z的值
- decode(value, if1, then1, if2, then2, ..., else)---- 如果value的值为if1,则回到then1的值,为if2, 回到then2的值,如果都不是,回到else的值。
2. 聚合表达式(分组表达式)
聚合表达式基于一组行来回到结果,为每一行回到一个值;
- sum()求和
- avg()求平均值
- count() 统计行数
- 一般使用count(1)来统计,也可以使用count(*),但不建议使用;
- 还可以使用count(列名)来统计,但是会出现一个问题,如果某条记录中用来统计但这个列名的值为空,则不会统计它,于是可能出现统计出的值比实际值小的情况。
- 例:
- max()求最大值
- min()求最小值
where不支持使用分组表达式,如果后面要跟分组条件过滤,使用having,having后面可以跟分组表达式。
3. 分析表达式
分析表达式一般用来做排名处理。分析表达式根据一组行来计算聚合值,用于计算完成聚集的累计排名等;分析表达式为每组记录回到多个行。
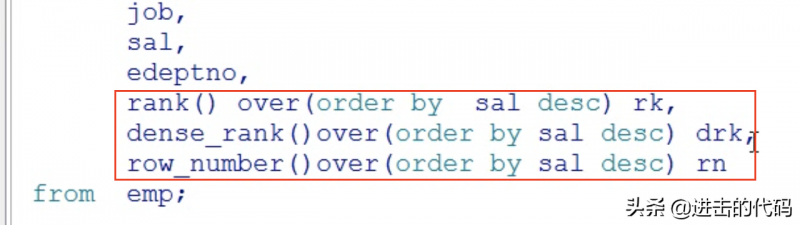
- rank( ) over( ):存在并列的情况 ,会发生跳跃

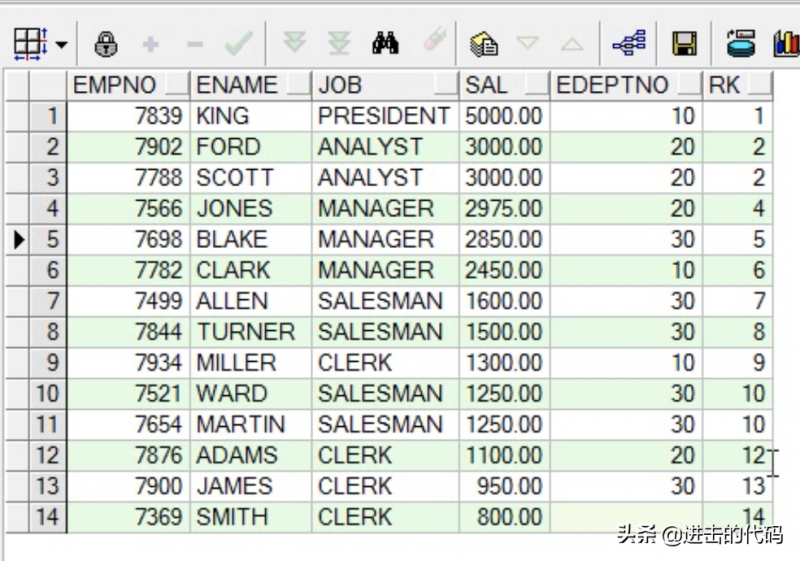
从rk的排名可以看出,排名会出现并列情况,并且下一名出现了跳跃。
- dense_rank( ) over( ):存在并列的情况 ,不会发生跳跃
- row_number( ) over( ):不存在并列的情况 ,不会发生跳跃
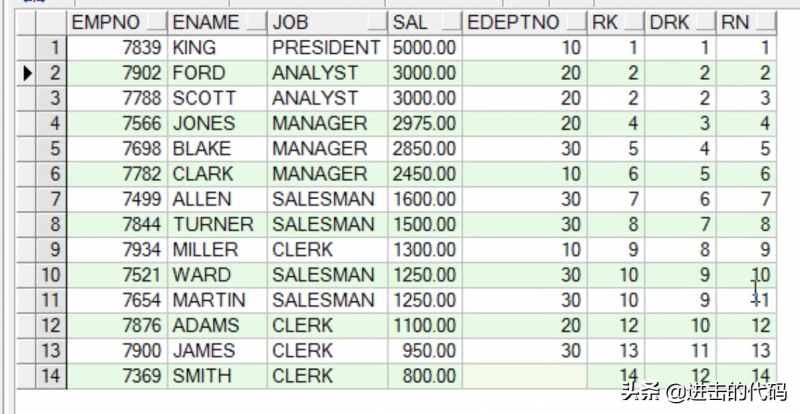
从drk可以看出,dese_rank()会出现并列情况,但是不会发生跳跃;
从rn可以看到row_number()既不会出现并列,也不会出现跳跃。
where后面也不能跟分析表达式。比如我们需要把上面结果加上薪资等于第二名的人,这时候我们不能在后面加where rk = 2,或者where rank() over(order by sal desc) = 2。这时可以在查出的结果外面再包一个select来进行查询,这是在where 后面加 rk = 2就可以了,就是把排名后的结果当作一张表,对这张表再次进行查询。

